class: center, middle, inverse, title-slide # Which Model for Poverty Prediction ## (Working Paper by Paolo Verme 2020) ### Philipp Kollenda ### Vrije Universiteit Amsterdam ### 18 June 2021 (last updated: 17 June 2021) --- # Why Targeting .pull-left[ 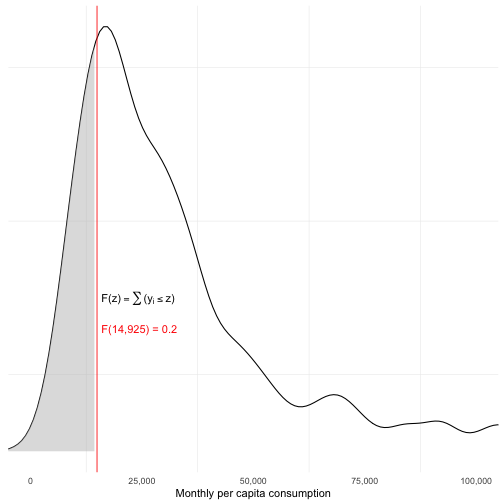<!-- --> ] .pull-right[ - Determine eligibility for a program. - Which measure? Which cut-off? > Consumption (Brown et al.; Verme), Rankings (Martin), ... > Absolute poverty (line) or relative poverty (rate) - The relevant measure may not be available for the entire sample 😢 - The relation between poverty line and poverty rate may be unknown 😢 ] ??? - Income distribution of the Uganda LSMS-ISA Training dataset (random subset of 50%). - If we know the income distribution we can set the poverty rate such that it exactly encompasses the chosen poverty line. But, if we do not know the income distribution we need to fix one of the two and the predicted distribution may be off (next slide). --- .pull-left[ ## How it started 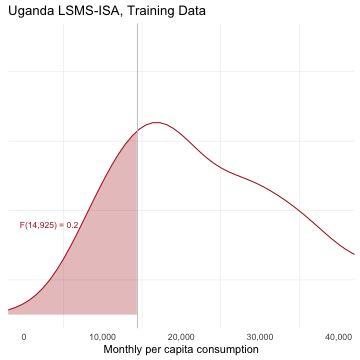<!-- --> ] .pull-right[ ## How it's going 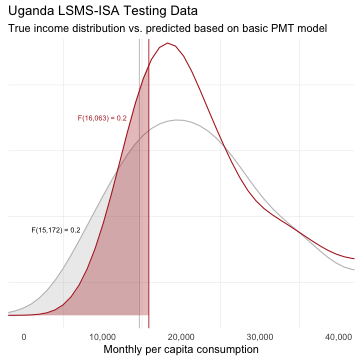<!-- --> ] - Fix poverty line at 14,925 is too low to reach the targeted 20 percent in the testing data. - Fix poverty rate at 16,063 (for 20 percent) is too high to reach the targeted 20 percent. ??? - Left is observed training data income distribution. Right is predicted income distribution for testing data, but the true underlying income distribution is not observed. - Again LSMS-ISA Uganda. OLS model like in Brown et al. - Brown et al. look at both and recommend in practice to fix the poverty rate (focus on exclusion error), Verme fixes poverty line and compares model performance when poverty line changes. --- name: modelling # A combined framework ### Brown et al. & Verme 1. **Modelling**: $$ \begin{align} y_i = \alpha + \beta x_i + \varepsilon_i \\\\ 1(y_i \leq z) = \alpha' + \beta' x_i + \epsilon_i \end{align} $$ Choice of outcome (consumption or poverty) and model (Verme: OLS/Logit + Random Forest and LASSO)<sup>1</sup>: 6 models 2. **Prediction** (out of sample): $$ \begin{align} \hat{y_i} = \hat{\alpha} + \hat{\beta} x_i \\\\ \hat{p}_i = P[y_i \leq z | x_i] = \hat{\alpha}' + \hat{\beta}' x_i + \epsilon_i \end{align} $$ .footnote[ [1] This is the part where Brown et al. compare OLS, quantile regression, *"poverty-weighted least-square"* for basic and extended set of covariates. ] ??? - Point for discussion: how important is training and testing versus simply estimating the model. - Smaller point, Verme splits error term into a random error and a modelling error, but those are not separately identifiable. --- ## A combined framework (cont.) 1. Modelling: `\(y_i = \alpha + \beta x_i + \varepsilon_i\)` 2. Prediction: `\(\hat{y_i} = \hat{\alpha} + \hat{\beta} x_i\)` <hr> 3. **Classification**: Use the predictions to classify into poor or non-poor $$ \begin{align} y_i \rightarrow \text{poor if }&\enspace \hat{y_i} \leq z \\\\ 1(y_i \leq z) \rightarrow \text{poor if }&\enspace \hat{p}_i \geq \tau \end{align} $$ `\(\tau\)` is a pre-specified probability cut-off (unclear what Verme uses). --- name: classificationerrors <script> function setColor(color){ document.getElementById("TN").style.backgroundColor='white'; document.getElementById("FP").style.backgroundColor='white'; document.getElementById("TP").style.backgroundColor='green'; document.getElementById("FN").style.backgroundColor='red'; }; </script> <script> function setColor2(color){ document.getElementById("TP").style.backgroundColor='white'; document.getElementById("FN").style.backgroundColor='white'; document.getElementById("TN").style.backgroundColor='green'; document.getElementById("FP").style.backgroundColor='red'; }; </script> # All classifications will have errors Poverty Confusion Matrix <table> <tr> <td> <td> <th> Predicted Non-Poor <th> <th> Predicted Poor <th> <tr> <tr> <th> Real Non-Poor <th> <td id="TN">True Negative (TN)<td> <td id="FP">False Positive (FP)<td> <tr> <tr> <th> Real Poor <th> <td id="FN">False Negative (FN)<td> <td id="TP">True Positive (TP)<td> </table> To evaluate different models we need a targeting measure (Verme: "*objective function*"). Verme: "coverage rate" (= 1 - Exclusion Error Rate, `\(1-\frac{\sum 1(\hat{y}_i > z | y_i \leq z)}{\sum 1(y_i\leq z)}\)`) <input id="button1" type="button" value="show" onclick="setColor('red')"> Verme: "leakage rate" (= Inclusion Error Rate, `\(\frac{\sum 1(y_i > z | \hat{y}\leq z)}{\sum 1(\hat{y}_i \leq z)}\)`)<input id="button2" type="button" value="show" onclick="setColor2('red')"> And some [additional measures](#measures) ??? We need a way to evaluate the different predictions. Typically we use the mean squared error: `\(\frac{1}{N}\sum_{i=1}^N(y_i - \hat{y}_i)^2\)`. But here we do not care about all errors equally. Instead, formulate targeting measure in terms of coverage of program. Exclusion Rate is share of true poor which are misclassified as non-poor. True poor are wrongly excluded. Inclusion Rate is share of predicted poor (Ravallion, true poor Verme) which are misclassified as poor. True non-poor are wrongly included. --- # Verme: Data and Results - 7062 households (3482 in testing data). - 6 models (OLS, Logit, Random Forest x2 , LASSO x2) at *"simplest Stata specification."* - Simplest consumption model: gender, age, marital status and skills of the head of the household, household size and urban-rural location <div id="htmlwidget-b27f42c8df6fe8cece8d" class="reactable html-widget" style="width:auto;height:auto;"></div> <script type="application/json" data-for="htmlwidget-b27f42c8df6fe8cece8d">{"x":{"tag":{"name":"Reactable","attribs":{"data":{"Measure":["Undercoverage (EER)","Leakage (IER)","Precision","Accuracy"],"Continuous_OLS":[0.4,0.24,0.7,0.68],"Continuous_Random Forest":[0.33,0.34,0.64,0.64],"Continuous_LASSO":[0.4,0.24,0.7,0.7],"Binary_Logit":[0.3,0.31,0.68,0.68],"Binary_Random Forest":[0.35,0.36,0.62,0.62],"Binary_LASSO":[0.3,0.31,0.68,0.68]},"columns":[{"accessor":"Measure","name":"Measure","type":"character","align":"left","headerStyle":{"background":"#f7f7f8"},"minWidth":140},{"accessor":"Continuous_OLS","name":"OLS","type":"numeric","align":"left","headerStyle":{"background":"#f7f7f8"}},{"accessor":"Continuous_Random Forest","name":"Random Forest","type":"numeric","align":"left","headerStyle":{"background":"#f7f7f8"}},{"accessor":"Continuous_LASSO","name":"LASSO","type":"numeric","align":"left","headerStyle":{"background":"#f7f7f8"}},{"accessor":"Binary_Logit","name":"Logit","type":"numeric","align":"left","headerStyle":{"background":"#f7f7f8"}},{"accessor":"Binary_Random Forest","name":"Random Forest","type":"numeric","align":"left","headerStyle":{"background":"#f7f7f8"}},{"accessor":"Binary_LASSO","name":"LASSO","type":"numeric","align":"left","headerStyle":{"background":"#f7f7f8"}}],"columnGroups":[{"name":"Continuous","columns":["Continuous_OLS","Continuous_Random Forest","Continuous_LASSO"]},{"name":"Binary","columns":["Binary_Logit","Binary_Random Forest","Binary_LASSO"]}],"defaultPageSize":2,"paginationType":"numbers","showPageInfo":true,"minRows":1,"highlight":true,"bordered":true,"dataKey":"5552f5c2d146918c41c577f577e2a92c","key":"5552f5c2d146918c41c577f577e2a92c"},"children":[]},"class":"reactR_markup"},"evals":[],"jsHooks":[]}</script> ??? - You can tell that it is a working paper... - Undisclosed middle-income-country - Poverty line set at median value. But unclear how exactly, probably look at the median value of the training data (or the entire data?). - Points to discuss: with so few variables, using regularization techniques like LASSO and Random Forest makes little sense. - Brown et al. had IER of 0.2-0.35 and EER of 0.25-0.45 for poverty line at 40 percent. --- # Verme: Coverage Curves <img src="Verme_CoverageCurves.png" width="504" style="display: block; margin: auto;" /> ??? - Verme plots coverage (1-EER) and leakage (IES) rate for different values of the poverty line for all three models. Unclear results, most clear for binary outcome and random forest dominated by logit and lasso. - Question: Is this the right comparison? The poverty line does not vary as much so it seems there are other parameters for which we would like to know how the dominance of models varies. Most notably we would want first a measure of precision, no? --- # Application: Uganda LSMS - 2744 observations and split them equally into training and testing data. - For fixed poverty line at `\(z=F^{-1}(0.2)\)` and fixed poverty rate at H=0.2, I calculate Headcount, IER and EER or TER using the basic and extended OLS model like in Brown et al. and add LASSO and Random Forest models. - Make 500 repeated testing - training splits and re-estimate the models to get bootstrapped precisions for the Headcount, IER, EER and TER prediction errors. - [Many limitations and to-do's](#limitations) ??? I was not convinced by the comparisons in the Verme paper. So, I did it again for the Uganda LSMS-ISA dataset which is used in the Brown et al. paper. The dataset has 2744 observations after cleaning everything, attempting to do it exactly like the Brown et al. paper. There are a couple of limitations (most importantly survey weights) but its a start. - Addition to Brown et al. Add machine learning techniques (LASSO and Random Forest) and divide into testing and training. - Addition to Verme. Use a more sophisticated consumption model where the ML techniques may have an advantage. Although it would still be better to have interaction terms and polynomials. - And then, I also get estimates of the precision of the predictions with the competing algorithms. --- name: myresults ## My results <img src="Slides_files/figure-html/uganda_results-1.png" style="display: block; margin: auto;" /> [Results for z=0.4](#ownz4results) ??? Brown et al. had IER = 0.403, EER = 0.619 and TER 0.344 for poverty line at 20 percent. --- ### Poverty rate at predicted poverty lines <img src="Slides_files/figure-html/hresults-1.png" style="display: block; margin: auto;" /> --- # Questions - In-sample versus out-of-sample testing. Is this crucial? Verme says: > The choice of the optimal model depends on the location of the poverty line, the choice of objective function and the particular income distribution at hand. Unlike current practices, it is essential to test alternative models and perform stochastic dominance analysis before selecting the optimal model How can we do this if we don't have the data and need to do out-of-sample validation? - How important is it to consider the precision of targeting models? Bootstrap reflects sampling uncertainty, but what if we have data of whole population? --- name: measures ### More Targeting Measures - Specificity Rate = 1 - Leakage Rate - Precision = TP/(TP+FP) *share of all predicted poor that are poor* - Accuracy = (TP+TN)/(TP+TN+FP+FN) *share of all observations correctly classified* - F2 = `\(5*TP/(5*TP+4*FN+FP)\)` 😕 - Chi2 = `\(\sum\frac{(O_{ij}-E_{ij})^2}{E_{ij}}\)` 😮 - Chi2 likelihood ratio <hr> [Back to presentation](#classificationerrors) --- name: limitations ### Limitations of Uganda Application - Survey weights are not used (not trivial with LASSO and Random Forest) - Clustering at region (ok) and PSU level (where in data?) - Correct bootstraps? Some people train on full sample and validate on sub-sample. I randomly split data but could also sample random subsets. Point estimate, first draw or average of bootstraps? <hr> [To results of application](#myresults) --- name: ownz4results ## My results <img src="Slides_files/figure-html/uganda_results4-1.png" style="display: block; margin: auto;" /> [Back to main results](#myresults) ??? Brown et al. had IER = 0.28, EER = 0.486 and TER 0.326 for poverty line at 40 percent.